Optimize the evaluation of IN for large lists using InSet#2156
Optimize the evaluation of IN for large lists using InSet#2156alamb merged 10 commits intoapache:masterfrom
IN for large lists using InSet#2156Conversation
| expr, | ||
| list, | ||
| negated, | ||
| if list.len() > OPTIMIZER_INSET_THRESHOLD && check_all_static_filter_expr(&list) { |
There was a problem hiding this comment.
According to Spark, default set 400.
There was a problem hiding this comment.
According to not support switch codeGen change to 10, like spark 2.x
| /// InSet | ||
| #[derive(Debug)] | ||
| pub struct InSet { | ||
| set: HashSet<ScalarValue>, |
There was a problem hiding this comment.
Just a note: because of using ScalarValue we are a bit slower than if we could use basic types, like HashSet<u32>, etc. The same apllies to the existing implementation based on . I think that could be a couple times faster.Vec
There was a problem hiding this comment.
But this makes something for a future PR
There was a problem hiding this comment.
@Dandandan Thanks for your information❤️, Is there any specific reason why using ScalarValue is slower?
There was a problem hiding this comment.
I think it's because ScalarValue is an enum of an option wrapper of value. So it would be overheads for both computation and memory footprint compared to HashSet of native data values.
There was a problem hiding this comment.
In addition to higher memory usage and dispatching overhead there are two extra sources of overhead
- Having to convert all values from array items to
ScalarValue - Hashing a
Scalarvalueis slower than hashing a native type.
 alamb
left a comment
alamb
left a comment
There was a problem hiding this comment.
Thank you @Ted-Jiang -- This is a (important) classic optimization.
I think the code is looking pretty good. The only thing I think this PR needs is some test(s) that exercise the new path.
| /// InSet | ||
| #[derive(Debug)] | ||
| pub struct InSet { | ||
| set: HashSet<ScalarValue>, |
| if let Some(in_set) = &self.set { | ||
| let array = match value { | ||
| ColumnarValue::Array(array) => array, | ||
| ColumnarValue::Scalar(scalar) => scalar.to_array(), |
There was a problem hiding this comment.
This is unfortunate -- turning a scalar into an array just to convert it back to a scalar if using InList
I wonder if we can pass the columnar_value to set_contains_with_negated and only do the conversion when using the Vec (not the Set)?
This probably doesn't really make any sort of performance difference for any case we care about, I just noticed it and thought I would mention it)
There was a problem hiding this comment.
Thanks! @alamb i agree it doesn't make any performance, it's rare to match ColumnarValue::Scalar
it also appears in https://github.com/apache/arrow-datafusion/blob/72a1194b9817df5ec7d87df6f5c3e45ed0e1ecd9/datafusion/physical-expr/src/expressions/in_list.rs#L517-L520.
Maybe we can file an issue to improve it.
Co-authored-by: Andrew Lamb <andrew@nerdnetworks.org>
| /// Value chosen to be consistent with Spark | ||
| /// https://github.com/apache/spark/blob/4e95738fdfc334c25f44689ff8c2db5aa7c726f2/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala#L259-L265 | ||
| /// TODO: add switch codeGen in In_List | ||
| static OPTIMIZER_INSET_THRESHOLD: usize = 10; |
There was a problem hiding this comment.
I don't think we should follow Spark, but should use some benchmarking to find a good heuristic for this threshold (where it's faster to use a hash set).
The optimal value might be quite a bit higher at this moment.
There was a problem hiding this comment.
Agree! i will post a bench result. By the way, without subquery implement, Is there some way easy to do?
There was a problem hiding this comment.
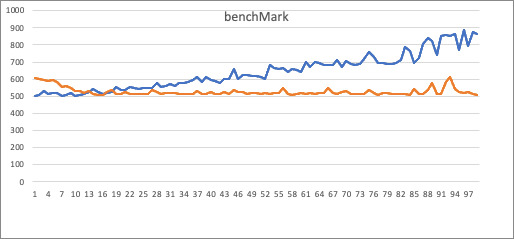
X: cost time. Y: filter value numbers
Blue: is use List, orange: is use Set.
I did a benchMark in my local, use select count(*) from orders where o_orderkey in (x1, x2, ..., xn)
Obviously, Set has a fixed gradient, List cost time increases with the parameter number.
The intersection of the two lines is located is between 10~20 (same as Spark set 10).
So, i decided set OPTIMIZER_INSET_THRESHOLD = 10 align with spark.
There was a problem hiding this comment.
Cool analysis!
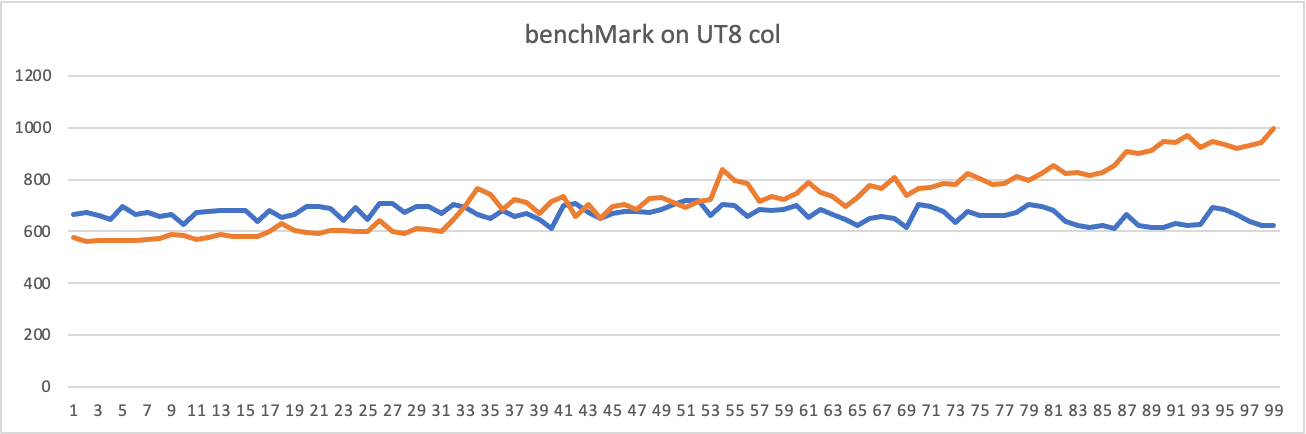
I am wondering if other data types make it a bit different, such as strings / utf8 arrays? I expect the conversion to be a bit slower there, because of the extra conversion/allocations needed.
There was a problem hiding this comment.
I have try to use cast 'u32.to_string' get same conclusion. In my opinion, use string may cause more cost in hash.
There was a problem hiding this comment.
btw: where array -> ScalarValue copies / allocates happened in code😂
There was a problem hiding this comment.
Amazing, thanks for the comparison. I would also be OK with changing it to some value like 30. Seems for both numeric as for utf8 data a good enough.
At some point we could further optimize the implementation (#2165) after this we can adjust to a (lower) value.
There was a problem hiding this comment.
where array -> ScalarValue copies / allocates happened in code
FYI, (String) allocations happen here, when converting to a ScalarValue. https://github.com/apache/arrow-datafusion/pull/2156/files#diff-ff8086fafbfe5021e5f7d51d96aaae2cf65f779ac3fae5fc182f87e956bb0550R214
| /// Size at which to use a Set rather than Vec for `IN` / `NOT IN` | ||
| /// Value chosen by the benchmark at | ||
| /// https://github.com/apache/arrow-datafusion/pull/2156#discussion_r845198369 | ||
| /// TODO: add switch codeGen in In_List |
There was a problem hiding this comment.
Yes change to discuss link in this pr.
IN for large lists using InSet
|
Thanks everyone who contributed code and review to this PR 🎉 |
| write!(f, "{} NOT IN ({:?})", self.expr, self.list) | ||
| } | ||
| } else if self.set.is_some() { | ||
| write!(f, "Use {} IN (SET) ({:?})", self.expr, self.list) |
There was a problem hiding this comment.
Sorry to bother you, is use in the "Use {} IN (SET) ({:?})" a typo? @Ted-Jiang
Which issue does this PR close?
Closes #2093.
Rationale for this change
@yjshen Thanks for your insight! ❤️
Optimized of In_List clause, when all filter values of In clause are static.
Default list values use
Vecto store, it has time complexity O(n) to checkcontains, In some situation useSetit has complexity O(1)test sql:
Master branch:
This pr:
What changes are included in this PR?
Are there any user-facing changes?